
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- opencv circle
- ubuntu 18.04 크롬설치
- 뮤지컬웨딩후기
- 우분투 서버변경
- opencv text
- react-typescript 예제
- opencv rectangular
- react-typescript example
- react 시작
- ubuntu kakao server
- nginx설치
- 뮤블리즈후기
- react-typescript
- mariadb
- 뮤블리즈
- mysql
- ubuntu 크롬 설치
- ubuntu chrome install
- PDO
- opencv opencv write
- opencv line
- 우분투 크롬
- react-typescript 환경변수
- react-typescript 환경설정
- 우분투 카카오서버
- react-typescript 시작
- php
- opencv
- ubuntu 18.04 서버 변경
- 우분투 크롬설치
- Today
- Total
대금부는 Programmer
네이버 뉴스 크롤링 ( selenium, beautifulSoup ) 본문
이번에는 네이버에서 검색창에 키워드를 입력하고, 키워드에 해당하는 뉴스 정보를 가져오는 작업을 할 예정이다.
우선, 네이버 뉴스 정보를 크롤링하는데 큰 틀은 아래와 같다.
1. 네이버에 키워드("코로나")를 검색한다.
2. 키워드로 검색된 페이지에서 뉴스 카테고리를 찾는다.
3. 뉴스 정보를 가져온다. ( 파란색 박스 ) // 참고로 네이버는 한 페이지에 10개의 뉴스정보를 제공한다.
- 상세한건 코드를 작성하면서 다루겠다. ( 페이징, 검색조건 등 )
- 그리고 크롤링 할때 사용되는 selenium 과 beautifulSoup를 둘다 사용 할 예정이다.
그럼 이제 작업을 시작해보자
작업을 시작하기전에 크롬드라버는 설치가 되어있다고 가정을 한다.
0. 크롬 드라이버를 불러오는 함수를 만들자.
# 크롬드리이버 생성
def chromeDriverCreate():
# user_agent를 변경을 위해, 나의 user_agent가 아닌 다른 사용자의 정보로 바꾸어준다.
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'
# 크롬드라이버 옵션 설정
options = Options()
# options.add_argument('headless') # 창을 띄우지 않고 크롤링한다. # 페이지 요소를 로드 안하기에 속도가 조금 개선됨.
# options.add_argument('window-size=1920x1080')
# options.add_argument("disable-gpu")
# user_agent 변경
options.add_argument(user_agent)
# 크롬드라이버 불러오기
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
return driver1. 네이버에 키워드를 입력하자.
* 1-1. 이제는 크롬 드라이버를 불러올 수 있는 상태이다. 크롤링 할 페이지의 url을 가져오자.
driver = chromeDriverCreate() # 크롬드라이버 불러오기
url = "https://www.naver.com" # 네이버 메인화면 url
driver.get(url) # 네이버 메인화면 열기* 1-2. 검색하는 공간의 id를 찾은 후에, 키워드를 입력하고 검색을 하자.
id를 찾으려면, 네이버 메인화면에서 F12를 눌러서 html 태그를 확인해보자.
html 태그 중 네이버 검색공간의 id를 확인해보면

못 찾겠으면, 네이버 화면에서 [ 우클릭 -> 검사 ]를 누르면 해당 태그가 있는곳으로 자동으로 이동된다.

keyword_input_space = driver.find_element_by_id('query') # 검색공간의 id를 가져온다.
keyword_input_space.send_keys(keyword) # 키워드를 입력한다.
keyword_input_space.submit() # 키워드를 검색한다. ( 엔터 )2. 다음화면으로 넘어갔을 것이다. 이제 뉴스 카테고리를 찾자!
* 화면을 보면 통합검색, 어학사전, 뉴스 등 많은 카테고리가 있다.
네이버 검색을 여러번 해봤는데, 이 카테고리의 순서가 보장이 안되었다. ( 뉴스 카테고리가 안보이는 경우도 있음 )
( * 뉴스 카테고리 안보이면 더 보기 탭을 눌러서 찾아야한다. )
그래서 카테고리의 이름이 "뉴스"와 같을때, 해당 카테고리를 클릭해서 뉴스 탭으로 이동하도록 하였다.
우선, 역시 가장먼저 해야할건, html태그 구조를 확인 하는 것이다.
카테고리 정보는 [ ul (.base) 밑인 li 태그 안에 존재한다. ]
그럼 li 태그 정보에서 카테고리를 찾아야한다.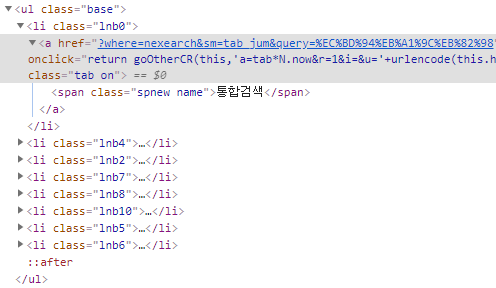
category = driver.find_element_by_xpath('//*[@id="lnb"]/div/div[1]/ul') # ul (.base) 의 xpath 정보
category_news_index = 0 # 뉴스라는 카테고리는 몇번째에 위치할까?
# li 태그 안에는 카테고리 정보가 들어있다. 이 카테고리 정보를 가져오자.
# "뉴스" 카테고리를 찾으면 반복을 종료한다.
# 만약 "뉴스" 카테고리를 못 찾으면, 더 보기 탭을 눌러서 찾아야한다.
for news_index, category_text in enumerate(category.find_elements_by_tag_name('li')):
if category_text.text == "뉴스":
category_news_index = news_index + 1 # 뉴스카테고리 텍스트가 위치하는 곳
break
else:
category_news_index = -1 # 뉴스카테고리 텍스트가 없는 경우, 더 보기를 클릭해서 찾아야한다.
# 카테고리에 뉴스 탭이 안보이는 경우 -> 더보기에서 뉴스 탭을 찾아야한다.
# 네이버는 페이징 타입이 2가지가 있다. ( html 구조에서 xpath를 찾을때 값이 바뀜 )
# 찾으려는 카테고리가 바로 보일때, 더보기를 눌러서 카테고리를 찾아야할때 2가지로 나뉜다.
# 그래서 나는 페이징 타입을 2가지로 나눴다.
if category_news_index == -1:
paging_type = 2 # 네이버 페이징시 더보기에서 뉴스 탭을 찾으면 페이징타입을 2로 설정
add_show_btn = driver.find_element_by_xpath('//*[@id="_nx_lnb_more"]/a/span') # 더보기 탭의 xpath를 찾는다.
add_show_btn.click() # 더보기를 누른다.
time.sleep(1) # 데이터를 불러오기 까지 1초를 기다려준다.
add_category = driver.find_element_by_xpath('//*[@id="_nx_lnb_more"]/div/ul') # 더 보기를 눌렀을때 많은 카테고리 항목들이 뜬다.
# 많은 카테고리 항목들중 또 뉴스탭을 찾아야한다.
for category_index, category_name in enumerate(add_category.find_elements_by_tag_name('li')):
if category_name.text == "뉴스":
category_news_index = category_index + 1
break
else:
category_news_index = -1
# 찾은 뉴스 탭을 클릭한다.
driver.find_element_by_xpath('//*[@id="_nx_lnb_more"]/div/ul/li['+str(category_news_index)+']').click()
else:
paging_type = 1 # 네이버 페이징시 뉴스 카테고리를 바로 찾았다면, 페이징타입을 1로 설정
# 찾은 뉴스 탭을 클릭한다.
driver.find_element_by_xpath('//*[@id="lnb"]/div/div[1]/ul/li['+ str(category_news_index)+']/a').click()
#네이버는 뉴스를 관련도순, 최신순, 오래된 순으로 분류한다. ( 기본값은, 관련도순이다. )
# 최신순으로 설정하고 싶으면 아래 주석을 풀면됨.
# driver.find_element_by_xpath('//*[@id="main_pack"]/div[1]/div[1]/div[3]/ul/li[2]/a').click() # 최신순 클릭
# 오래된순으로 설정하고 싶으면 아래 주석을 풀면됨
# driver.find_element_by_xpath('//*[@id="main_pack"]/div[1]/div[1]/div[3]/ul/li[3]/a').click() # 오래된순 클릭
3. 이제 원하는 뉴스정보가 보일것이다. 원하는 내용만 들고오자.
나는 뉴스의 제목과 뉴스의 링크만 들고올 생각이다.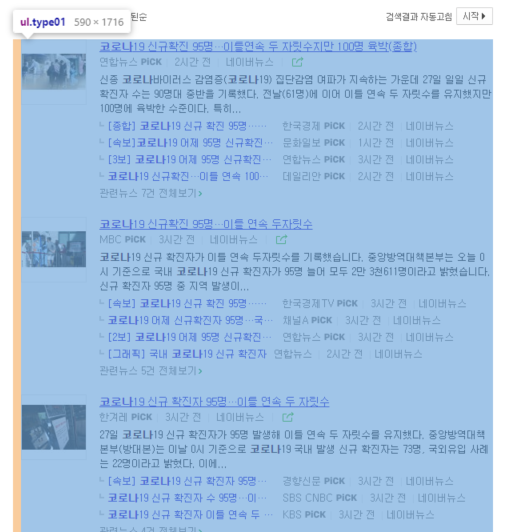
# 페이지에 있는 html 태그 텍스트를 가져온다.
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 뉴스정보가 있는 html 태그만 들고온다.
news_data = soup.find('ul', class_="type01")
# 뉴스정보의 갯수만큼 뉴스 데이터를 가져온다.
for index, text in enumerate(news_data):
# 태그로 검색해서만 찾을예정
if type(text) is not bs4.element.NavigableString:
# 뉴스의 제목
news_title = text.findChild('dl').findChild('dt').findChild('a')['title']
# 뉴스의 링크
news_link = text.findChild('dl').findChild('dt').findChild('a')['href']
이렇게 하면 뉴스의 제목과 링크정보를 다 가져 올 수 있다.
사용자가 원하는 뉴스의 갯수와 페이징 하는 방법도 설명하고 싶은데 귀찮다.
사실, 페이징을 하는건 어렵지 않다.
원하는 태그의 주소값 ( xpath, id, css_selector ... ) 등을 찾고 본인이 생각한대로 움직이게 하면된다.
예를 들면,
첫 페이지에서 뉴스 10개를 들고왔다. 근데, 나는 2번째 페이지의 뉴스정보도 가져오고싶어!!
이러면 페이징 하는부분에서 2페이지를 클릭해서 위 작업을 반복하면 된다.
이어서, 다른 키워드로 검색해서 뉴스를 가져오고싶어! 이러면 위 작업이 끝난뒤 새 페이지를 열고 반복하면된다.
또는 메인페이지로 이동시키거나,.. 생각하기 나름인것 같다.
크롤링 하기전에는 본인이 어떤 방식으로 데이터를 크롤링해올것인지 명확해야한다.
마지막으로 파이썬 패키지를 만들어서 배포할 예정인데, 배포가 완료가 되면 글을 수정하겠다.